Apparently, storage blocks on Amazon EBS volumes that were restored from
snapshots incur in significant latency penalties on I/O operations the first
time they’re accessed. According to the user guide:
New EBS volumes receive their maximum performance the moment that they are
available and do not require initialization (formerly known as pre-warming).
However, storage blocks on volumes that were restored from snapshots must be
initialized (pulled down from Amazon S3 and written to the volume) before you
can access the block. This preliminary action takes time and can cause a
significant increase in the latency of an I/O operation the first time each
block is accessed. For most applications, amortizing this cost over the
lifetime of the volume is acceptable. Performance is restored after the data
is accessed once.
This can be particularly painful when restoring Amazon RDS DB snapshots, as the
performance can be severely impacted. In order to overcome the first touch
penalty, it is advisable to warm up the disk by performing a full table scan or
a vacuum on all tables in the database.
Tracking PostgreSQL Execution Statistics on Amazon RDS
I’ve recently been working with PostgreSQL on Amazon RDS
and found out about the pg_stat_statements module, which
allows tracking execution statistics of all SQL statements executed by the
server. It can be very helpful when monitoring your application and discovering
about slow running queries. It is also very easy to set up.
Enabling it on Amazon RDS
Setting it up on Amazon RDS is easy, but does require rebooting your
database. First, go to your AWS Console and create a new parameter
group or modify one of the existing ones. You should find the Parameter Groups
option on the sidebar to your left (at least in the current version of the
interface). First, you should include pg_stat_statements as a shared library
to preload into the server. In order to do so, include the pg_stat_statements
string in the shared_preload_libraries parameter. The value of the parameter
should be a comma-separated list of libraries to preload. Chances are that the
value is currently empty, so you’d only need to set it to pg_stat_statements.
Afterwards, you should set the pg_stat_statements.track parameter to ALL,
enabling tracking of all queries, even those inside stored procedures. If you
use and want to keep track of large-sized queries, you should also increase the
track_activity_query_size parameter value. Its value specifies the number of
bytes reserved to track the currently executing command for each active session.
The default value is 1024 but you might want to increase it.
Once you have a parameter group with the relevant parameters defined, you must
modify your database to use the new parameter group (if you edited one the
database was already using then that’s not necessary) and reboot your database.
Rebooting is necessary because libraries set in the shared_preload_libraries
parameter will only be loaded at server start. Once rebooted, connect to your
database as an RDS superuser and run the following commands to enable the
extension and make sure it was set up properly:
If it returns one row of query statistics information then it’s set up properly.
If not, you might not have restarted your database or have a misconfigured
instance.
The pg_stat_statements View
The main thing the module provides is the pg_stat_statements view. The view
allows you to query statistics about the execution of SQL statements in the
server. The official documentation provides a complete
description of all columns the view provides, but the ones I find most useful are:
Name
Description
query
Text of a representative statement.
calls
Number of times executed.
total_time
Total time spent in the statement, in milliseconds.
min_time
Minimum time spent in the statement, in milliseconds.
max_time
Maximum time spent in the statement, in milliseconds.
mean_time
Mean time spent in the statement, in milliseconds.
rows
Total number of rows retrieved or affected by the statement.
According to the documentation, two plannable queries (SELECT, INSERT,
UPDATE and DELETE) will be considered the same if they are semantically
equivalent except for the values of literal constants appearing in the query.
This means that identical queries will be combined into a single entry in the
view.
I like to keep track of queries in which the server is spending most of the time, so I usually run:
Ocasionally, it might be necessary to reset the view. I tend to reset it before
running a stress test or otherwise to clean old data. In order to do so, the
module provides the pg_stat_statements_reset() function. To discard all
statistics gathered so far, simply run:
SELECTpg_stat_statements_reset();
If you want to know more about the module,
the official documentation is a good place to start. You
should also find instructions there on how to set it up in your own managed
instance.
Yesterday, I started solving a series of small programming puzzles in
Advent of Code. You get one puzzle per day, as a proper advent
calendar. So far, each puzzle is divided in two parts, granting a maximum of two
stars per puzzle. The two parts of a puzzle use the same input and the second
part is usually a simple variation of the first one. You only have to submit the
output to the provided puzzles, so it’s possible to do things by hand, albeit
unlikely. The puzzles so far have been simple, either by definition, or by
having small input sizes, thus not requiring efficient algorithms to be solved.
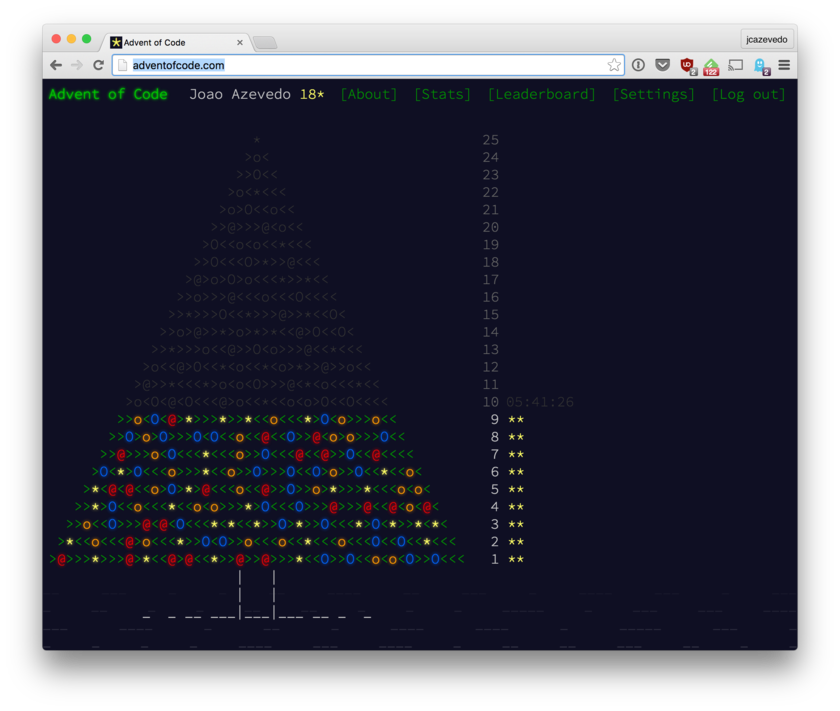
The tree lights up as you go along, giving it a nice effect:
Advent of
Code tree with 9 levels lit up.
I’ve decided to solve them all in Scala. Initially I started in C++, but in
day 4’s puzzle it was required to find MD5 hashes and I decided to
leverage Java and Scala’s standard library to ease up the process, sticking with
it for the rest of the puzzles (so far).
Genres are usually neglected in my music library metadata. My primary source for
music metadata doesn’t do genres and therefore I tend not to worry
too much about them. However, I usually rely on rateyourmusic.com to
discover new music, either by peeking at the ratings or by searching through
genres of albums that I enjoyed. Rateyourmusic attributes genres to albums based
on community voting and keeps a tree of genres whose structure is
also voted upon. I tend to find its genre information fairly accurate and more
often than not I find myself browsing through the “best” albums of a given
genre on the site.
Locally, I use beets to manage my music library. It’s a great piece of
software and I’ve been increasingly using its querying capabilities to populate
my playlists. Being able to do the same sort of genre-based queries I do on
Rateyourmusic locally would therefore be awesome.
Beets has a plugin to fetch genre data from last.fm tags:
LastGenre. There are a couple of issues I identify with using
last.fm tags as genres:
To be reasonably accurate, one should use the album or track tags. However,
those are usually neglected by users, who tend to tag artists mostly.
There’s no hierarchy in the tags (one needs to
build it externally). I would like to, for example, be
able to search for Ambient and get albums of both Ambient Techno and
Dark Ambient.
Taking that into account, I decided to write a plugin to fetch genre information
from Rateyourmusic and assign it to albums and items in the beets library:
beets-rymgenre. Rateyourmusic doesn’t provide a webservice or
API for developers to build upon1 so it’s necessary to scrape for the
desired information. Beets is written in Python, and so are its plugins. I have
little experience with it and no familiarity with its ecosystem. I ended up
using lxml for scraping and requests for the HTTP client,
but more lightweight solutions may exist.
I’ve already populated some albums in my library with genre information and I’m
happy with the plugin so far. A great plus of having genre information in the
library metadata is that now I can ask beets for random albums of a given genre
(or set of genres, for that matter) whenever I’m not sure what to listen to
next.
There’s actually an open ticket to build a webservice /
API for Rateyourmusic open since 2009! ↩
I confess that this site has been neglected for far too long. Yesterday I
thought that it deserved some attention and tried to improve its design a bit. I
like clean, hassle-free designs. The previous looks of this site was my attempt
at that. It was rushed though. The fonts were not thoroughly chosen, and it
didn’t look good on mobile devices. This time around, I decided to get a
stronger inspiration from people that know what they’re doing. I first started
to look at themes for Jekyll, as it is the generator that is currently
powering this site. Eventually I came around at Poole, a sort of helper
for Jekyll. Poole currently supports two official themes: Hyde and
Lanyon. I like Hyde’s fonts, but not its sidebar, so I adapted its CSS
stylesheet to suit my tastes, using what Poole calls the masthead to have the
site name and main navigation links. I’m pretty satisfied with the end result,
and it is now finally readable on mobile devices. Let’s hope this provides me
with extra motivation to push new content more frequently.